本文共 8228 字,大约阅读时间需要 27 分钟。
查看专栏更多内容:
相关实战:
关系数据库标准语言SQL
写下博客用于自我复习、自我总结。 如有错误之处,请各位指出。
结构化查询语言 SQL(Structured Query Language)是关系数据库的标准语言,自 SQL 成为国际标准语言后,各个数据库厂家纷纷推出了各自的 SQL 软件或与 SQL 的接口软件。这就使大多数数据库均用 SQL 作为共同的数据存取语言和标准接口,使不同数据库系统之间的互操作有了共同的基础。
之前已经提到过,MySQL和Oracle会有一些不同,在本文中将不做区分。笔者使用的是MySQL数据库,但不是使用命令行或者PHP等,而是使用MySQL管理工具SQL_Front。 大家用的工具可能不同,但总体功能应该差别不大,以下内容就以SQL_Front为例。
在具体操作数据前,首先需要创建一些数据,之后的演示就将以这个 学生-课程数据库 为例来说明,之后就不再赘述。
 Sno:学号 Sname:姓名 Ssex:性别 Sage:年龄 Sdept:所在系 Cno:课程号 Cname:课程名 Cpno:先修课 Ccredit:学分 Grade:成绩
Sno:学号 Sname:姓名 Ssex:性别 Sage:年龄 Sdept:所在系 Cno:课程号 Cname:课程名 Cpno:先修课 Ccredit:学分 Grade:成绩 创建数据库
在数据库界面中,找到输入SQL编辑器,之后只需要把SQL语句写入并运行,就可作出相关操作了。
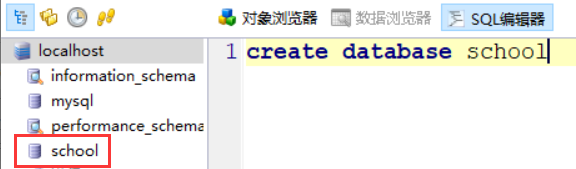
 想要创建数据库,使用 create 命令:
想要创建数据库,使用 create 命令: CREATE DATABASE 数据库名;
若想要删除数据库,使用 drop 命令:
drop database 数据库名;
补充:SQL语句推荐使用大写,但是使用小写也可以,没有硬性要求。
举例:
运行之后,数据库就创建成功了
 删除也仍然成功
删除也仍然成功 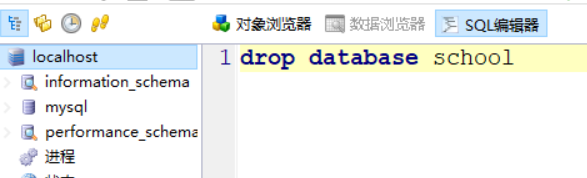
除此以外,创建数据库时,有需要注意的问题。
 在创建数据库时,我们可以选择字符集和字符集校对。它们的作用看这一篇就明白了:
在创建数据库时,我们可以选择字符集和字符集校对。它们的作用看这一篇就明白了: 我们用SQL语句,就可以这么定义:
CREATE DATABASE IF NOT EXISTS school DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
需要修改只需要改上面的部分内容即可。这条语句的作用是:
- 如果数据库不存在则创建,存在则不创建。
- 创建school数据库,并设定编码集为utf8。
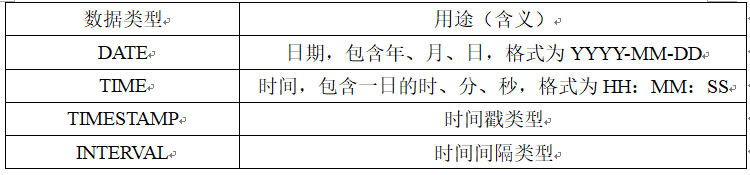
数据类型
在继续下面的内容前,需要先介绍一下数据库中的数据类型。
我们知道关系模型中一个很重要的概念是域。每一个属性来自一个域,它的取值也必须是域中的值。在SQL中的域的概念用数据类型来实现。它和其它语言数据类型的不同是,定义表的各个属性时不仅需要指明其数据类型,还要指明其长度。需要注意的是,不同的关系数据库管理系统中支持的数据类型不完全相同!
在这里就总结几个常用的,更详细的内容可以参考文档:

 一个属性选用哪种数据类型要根据实际情况来决定,一般要从两个方面来考虑,一是取值范围,二是要做哪些运算。比如,对于年龄(Sage)属性,可以采用 CHAR(3) 作为数据类型,但考虑到要在年龄上做算术运算(如求平均年龄),所以要采用整数作为数据类型,因为在CHAR(n)数据类型上显然不能进行算术运算。而整数又分为很多种,因为一个人的年龄在百岁左右,所以选用短整数作为年龄的数据类型。
一个属性选用哪种数据类型要根据实际情况来决定,一般要从两个方面来考虑,一是取值范围,二是要做哪些运算。比如,对于年龄(Sage)属性,可以采用 CHAR(3) 作为数据类型,但考虑到要在年龄上做算术运算(如求平均年龄),所以要采用整数作为数据类型,因为在CHAR(n)数据类型上显然不能进行算术运算。而整数又分为很多种,因为一个人的年龄在百岁左右,所以选用短整数作为年龄的数据类型。 数据定义
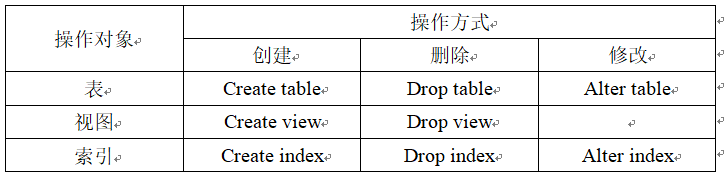
创建基本表
在创建好数据库之后,接下来就是创建基本表。
创建MySQL数据表的SQL通用语法:
CREATE TABLE table_name (column_name column_type);
建表的同时,我们就可以定义列名和其数据类型。
除此以外,我们还可以定义与该表相关的完整性约束条件。这些完整性约束条件会被存入系统的数据字典中,当用户操作表中数据时由关系数据库管理系统自动检查该操作是否违背这些完整性约束条件。如果完整性约束条件涉及该表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级。
那在本次学生-课程数据库 例中,我们就这样建表:
CREATE TABLE Student(Sno CHAR(9) PRIMARY KEY, /*列级完整性约束条件,Sno是主码*/Sname CHAR(20) UNIQUE, /*Sname取唯一值*/Ssex CHAR(2),Sage SMALLINT,Sdept CHAR(20));
系统执行该语句后,就会在数据库中建立一个新的空Student表,并将有关Student表的定义以及有关约束条件存放在数据字典中。
CREATE TABLE Course(Cno CHAR(4) PRIMARY KEY, /*列级完整性约束条件,Cno是主码*/Cname CHAR(40) NOT NULL, /*列级完整性约束条件,Cname不能取空值*/Cpno CHAR(4), /*Cpno的含义是先修课*/Ccredit SMALLINT,FOREIGN KEY(Cpno)REFERENCES Course(Cno)/*表级完整性约束条件,Cpno是外码,被参照表是Course,被参照列是Cno*/);
该语句说明参照表和被参照表可以是同一个表。
CREATE TABLE SC(Sno CHAR(9),Cno CHAR(4),Grade SMALLINT,PRIMARY KEY(Sno,Cno), /*主码由两个属性构成:必须作为表级完整性进行定义*/FOREIGN KEY(Sno)REFERENCES Student(Sno),/*表级完整性约束条件,Sno是外码,被参照表是Student*/FOREIGN KEY(Cno)REFERENCES Course(Cno)/*表级完整性约束条件,Cno是外码,被参照表是Course*/);
在这里,因为主码由两个属性(即属性组)构成,所以必须作为表级完整性进行定义,如果作为列级完整性,会因为主码存在两个而报错。
相关说明:
完整性约束条件其实还有一些,用法都是相同的,具体可以看这篇文章:
再把剩下的内容用一个例子来说明:
CREATE TABLE test(ID INT PRIMARY KEY AUTO_INCREMENT,sex CHAR(2) NOT NULL DEFAULT '男',CHECK(sex in('男','女'))); 该例中:
添加了自增的约束性条件AUTO_INCREMENT,它一般用于主键,数值会自动加1;
添加了默认值的约束性条件DEFAULT;
添加了指定取值的约束性条件CHECK。
因为这几个约束性条件的存在(AUTO_INCREMENT、DEFAULT、CHECK),所以在插入数据时是会有限制的。
为了更好的说明,在这里先简单介绍一下,插入数据的语句。在下面就会具体说一下INSERT语句:
INSERT INTO <表名> values( <常量1> [, <常量2> ] ... )
在这个用法中,valuse中常量的排列顺序,要和建表时列的顺序去对应噢。
(<>中的内容为必选项,[]中的内容为可选项) 如果我们想为设置了AUTO_INCREMENT的列,设置起始值,这会有两种方法。
一种是在创建表的时候设置:
CREATE TABLE test(ID INT PRIMARY KEY AUTO_INCREMENT,sex CHAR(2) NOT NULL DEFAULT '男',CHECK(sex in('男','女')))AUTO_INCREMENT = 100; 一种是在插入数据的时候设置(注意:一定是未用第一种方法设置时才能这么用,也就是现在数据表中的数据全为空的时候):
insert into testvalues (100, DEFAULT);
如果此时,数据表中存在数据,也就是ID已经从某初始值开始自增加,那么我们就不能在ID列上为其再赋予一个具体的值,也就是上面的INSEET用法会报错。
那我们现在该如何在已有的ID的基础上增加数值呢?此时我们可以这么做:
insert into testvalues (NULL, DEFAULT)insert into testvalues (DEFAULT, DEFAULT)
ID字段为NULL或DEFAULT都是自增长。
又或者不指定id,那么id就会在已有的值上自增长。
INSERT test(sex) VALUES(DEFAULT);
对于DEFAULT的用法,在上面我们已经看到了。只要在插入数据时,设置为DEFAULT,那么它的值就会选择默认值。当然也可以为其设置其它值。而由于在这里使用了CHECK,所以它的取值也只能是在CHECK所限定的域的取值(范围)。在这里就意味着,sex值只能为字符串类型的男或女,如果插入其它值,用SQL语句就会报错(手动插入倒是无所谓)。
除此以外,CHECK还有其它用法:
check(ssex in ('f','m')):让数据只能取限定的
check(sno like '[a-z][0-9][0-9]'):让数据按照限定格式书写 check(grade between 0 and 100):让数据在指定范围 不在创建表的时候定义这些约束也没关系,之后仍然可以修改。
修改基本表
随着应用环境和应用需求的变化,有时需要修改已经建立好的基本表。SQL语言用ALTER TABLE语句修改基本表(但在具体使用时,不一定能这么使用),其一般格式为:
ALTER TABLE <表名> [ADD [COLUMN] <新列名> <数据类型> [完整性约束]][ADD <表级完整性约束> ][DROP [COLUMN] <列名> ];[DROP CONSTRAINT <完整性约束名> ][ALTER COLUMN <列名> <数据类型> ]
(<>中的内容为必选项,[]中的内容为可选项)
其中,
ADD子句用于增加新列、新的列级完整性约束条件和新的表级完整性约束条件。
DROP COLUMN子句用于删除表中的列。
DROP CONSTRAINT子句用于删除指定的完整性约束条件。
ALTER COLUMN子句用于修改原有的列定义,包括修改列名和数据类型。(如果不能使用,请参考下面的change和modify子句)
补充说明MySQL修改字段的用法:
alter table 表名 change 旧字段名 新字段名 字段类型 约束条件;alter table 表名 modify 字段名 字段类型;// 仅修改字段类型
(这部分对于Oracle和MySQL可能会不同,亲测某些语句MySQL中可以执行,Oracle中则不行,如果出现报错信息,请多多尝试!)
例如(MySQL):
(1)向Student表中增加“入学时间”列,其数据类型为日期型。
ALTER TABLE StudentADD S_entrance DATE;
(2)将年龄的数据类型由字符型(假设原来的数据类型是字符型)改为整数。
ALTER TABLE StudentMODIFY Sage INT;
(3)修改DEFAULT默认值
alter table test change sex sex char(2) default '1'
(4)增加课程名称必须取唯一值的约束条件。
ALTER TABLE CourseADD UNIQUE(Cname)
(5)修改AUTO_INCREMENT起始值
ALTER TABLE testAUTO_INCREMENT = 500;
(6)修改CHECK域范围
ALTER TABLE testADD CHECK(sex in('1','2')); (7)删除字段
ALTER TABLE testDROP S_entrance;
更多内容可以参考:
删除基本表
DROP TABLE table_name ;
建立索引
对于索引,在上一篇文章中已经有所提到,现在再叙述一下:
索引: 使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。
所以我们可以这样理解:主键相当于是书籍的页码,我们根据页码就能找到这一页。而索引相当于是书籍的目录,有了目录我们可以很快的知道这本书的基本内容和结构。
也就是说,当表的数据量比较大的时候,查询操作显然会比较耗时,此时我们建立出索引就是加快查询速度的一种有效手段。
补充说明:
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。这也就导致了,虽然使用索引会加快查询速度,但是我们不能过多的使用索引,因为这会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。这是因为在更新表时,MySQL不仅要保存数据,还要保存索引文件。
建立索引会占用磁盘空间的索引文件。
具体使用:
(1)建立索引:
CREATE [UNIQUE] INDEX <索引名> ON <表名> ( <列名> [ <次序> ] [, <列名> [ <次序> ]])
(<>中的内容为必选项,[]中的内容为可选项)
UNIQUE和之前约束条件一样,指的是此索引的每一个索引值只对应唯一的数据记录。
这里的次序可有两种,ASC(升序)、DESC(降序),默认值为ASC。它们在之后的数据查询时也会使用到。
例:
CREATE UNIQUE INDEX Stusno ON Student(Sno);CREATE UNIQUE INDEX Coucno ON Course(Cno);CREATE UNIQUE INDEX Scno ON SC(Sno ASC,Cno DESC);
(2)修改索引名:
ALTER INDEX <旧索引名> RENAME TO <新索引名>
例:
ALTER INDEX SCno RENAME TO SCSno;
(3)删除索引:
DROP INDEX <索引名> [ON <表名> ]
例:(假如存在该索引)
DROP INDEX Stusname;
更多内容请参考:
数据定义这部分的基本的操作:
(视图将会在下一篇文章中介绍)
数据更新
因为数据查询内容较多,在这里先介绍数据更新内容。
数据更新操作有三种:向表中添加若干行数据、修改表中的数据和删除表中的若干行数据。
插入数据
SQL的数据插入语句INSERT通常有两种形式,一种是插入一个元组,一种是插入子查询结果。后者可以一次插入多个元组。
基本格式:
INSERT INTO <表名> [( <属性列1> [, <属性列2> ] ... )]VALUES( <常量1> [, <常量2> ] ... );
(<>中的内容为必选项,[]中的内容为可选项)
例:将一个新学生元组(学号:201215128,姓名:陈冬,性别:男,所在系:IS,年龄:18岁)插入到Student表中。
INSERT INTO Student(Sno,Sname,Ssex,Sdept,Sage)VALUES('201215128','陈冬','男','IS',18);/*字符串常数要用单引号或双引号括起来*/ 说明: 在这里的属性列是可选项。也就是说,我们可以通过这种指定的方式来指出新增加的元组在哪些属性上去赋值。指定后,新增的元组中属性的顺序就可以与原本表中列的顺序不同。如果不指定,那INSERT就会根据该表列的顺序去插入。
比如:在上例中指定的属性列的顺序和该表列的顺序相同,我们就可以不指定属性列。
(所以需要注意插入数据的顺序是否正确!)INSERT INTO StudentVALUES('201215128','陈冬','男','IS',18); 除此以外,我们也可以插入部分属性列的数据。例如:
INSERT INTO Student(Sno,Sname)VALUES('201215128','陈冬'); 这时,其它列的值将会自动地赋予空值。但需要注意的是这样做是否能够满足约束条件(如:设置了数据非空 或者 主键不能为空)等一系列限制。
我们还可以这样做:
INSERT INTO StudentVALUES('201215128','陈冬',NULL,NULL,NULL); 因为这种方式没有给定属性列,所以无法判断新增常量值与哪一属性列对应。因此很显然,在这种方式下我们需要明确给出空值。(显然在这种情形下,第一种用法就很好用了)
上述还提到了,我们可以插入子查询结果,能这么做也是因为查询结果就可以当作一个新增元组看待。
基本格式:
INSERT INTO <表名> [( <属性列1> [, <属性列2> ] ... )]子查询;
关于具体的如何查询将在下一篇文章中重点叙述,在这里简单举例。
查询的关键词是SELECT,简单格式如下:
SELECT <列名> FROM <表名>
例:
INSERT INTO TEST(Sdept)SELECT Sdept FROM Student
修改数据
修改操作又称为更新操作,其语句的一般格式为:
UPDATE <表名> SET <列名> = <表达式> [, <列名> = <表达式> ] ...[WHERE <条件> ]
其功能是修改指定表中满足WHERE子句条件的元组。其中SET子句给出<表达式>的值用于取代相应的属性列值。如果省略WHERE子句,则表示要修改表中的所有元组。
例1:修改某一个元组的值
UPDATE StudentSET Sage = 22WHERE Sno = '201215121'
例2:修改多个元组的值
UPDATE StudentSET Sage = Sage + 1
例3:带子查询的修改语句
UPDATE SCSET Grade = 0WHERE Sno IN ( SELECT Sno FROM Student WHERE Sdept = 'CS');
删除数据
删除语句的一般格式为:
DELETE FROM <表名> [WHERE <条件> ]
DELETE语句的功能是从指定表中删除满足WHERE子句条件的所有元组。如果省略WHERE子句则表示删除表中全部元组,但表的定义仍在字典中。也就是说DELETE语句删除的是表中的数据,而不是关于表的定义。
例1:删除某一个元组的值
delete from Student where Sno = "201215128";
例2:删除多个元组的值
DELETE FROM SC
例3:带子查询的删除语句
DELETE FROM SCWHERE Sno IN ( SELECT Sno FROM Student WHERE Sdept = 'CS');
在上面提到了,DELETE语句删除的是表中的数据,而不是关于表的定义。 其它的删除用法,在这里总结如下:
清除表内所有数据,保存表结构,用 truncate。格式为:
truncate table <表名>
例:清除学生表内的所有数据。
truncate table Student;
删除整个表用 drop。格式为:
drop table <表名> ;
例:删除学生表。
drop table Student;
即:
1、当你不再需要该表时, 用 drop;
2、当你仍要保留该表,但要删除所有记录时, 用 truncate;
3、当你要删除部分记录时, 用 delete。
转载地址:http://amyki.baihongyu.com/